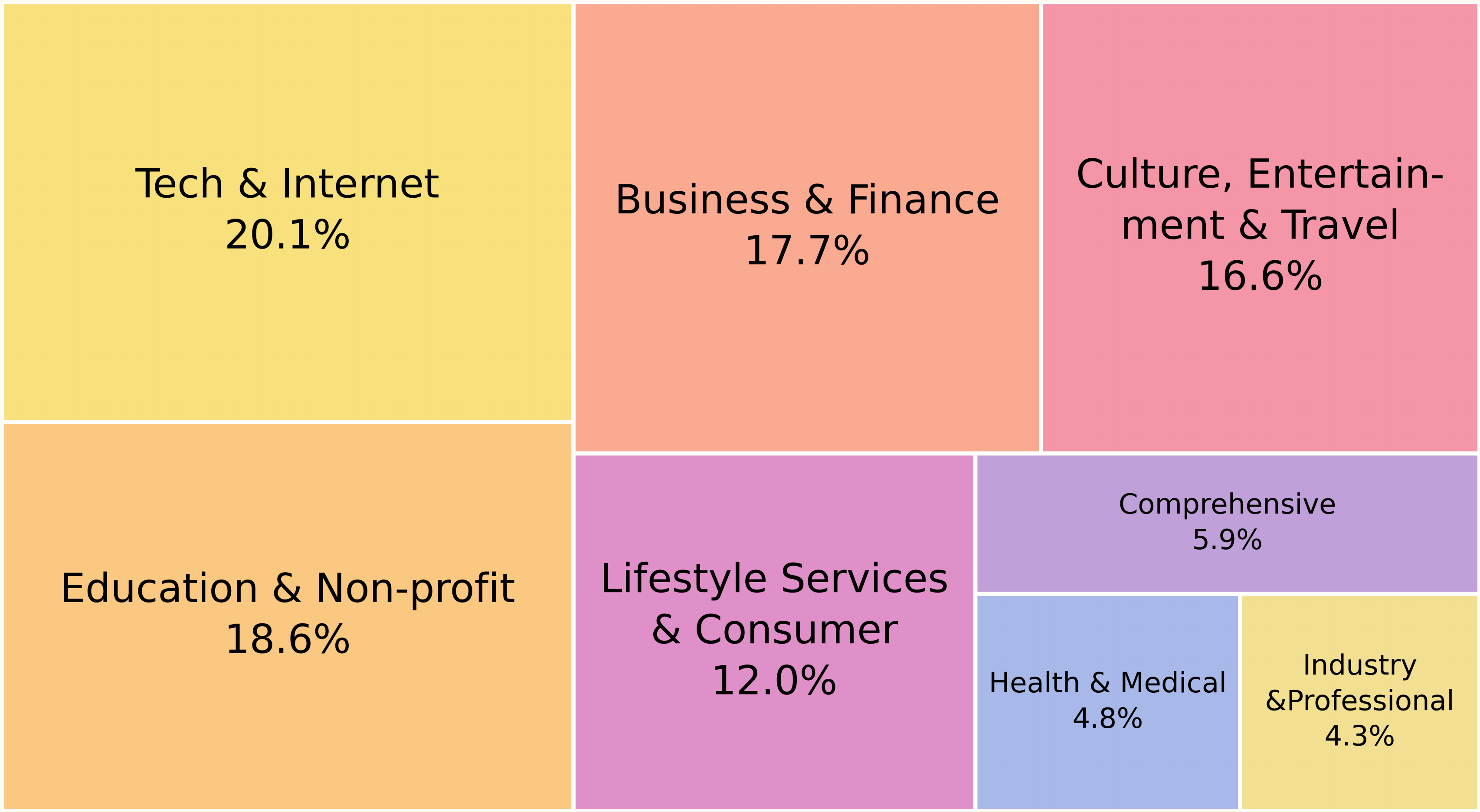
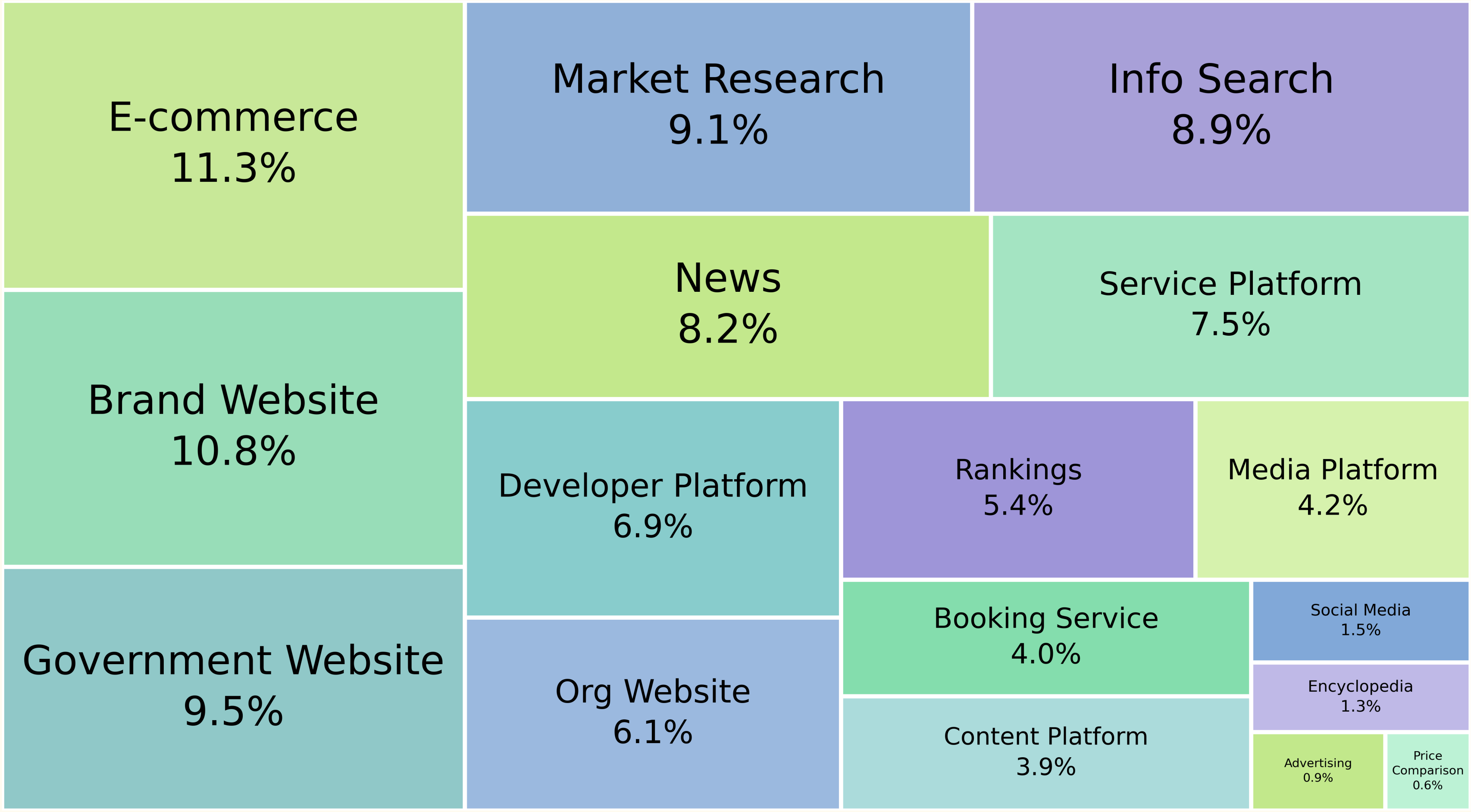
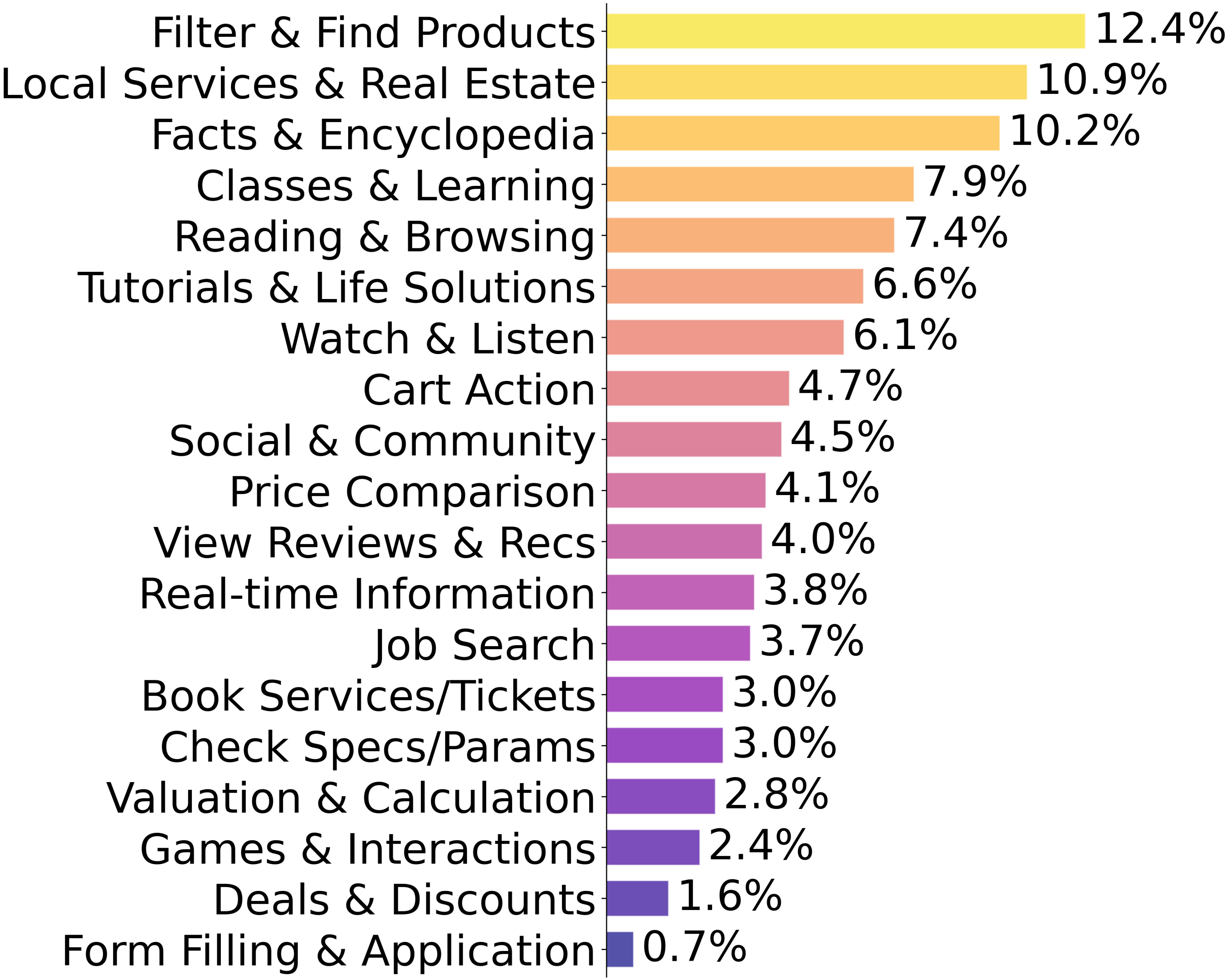
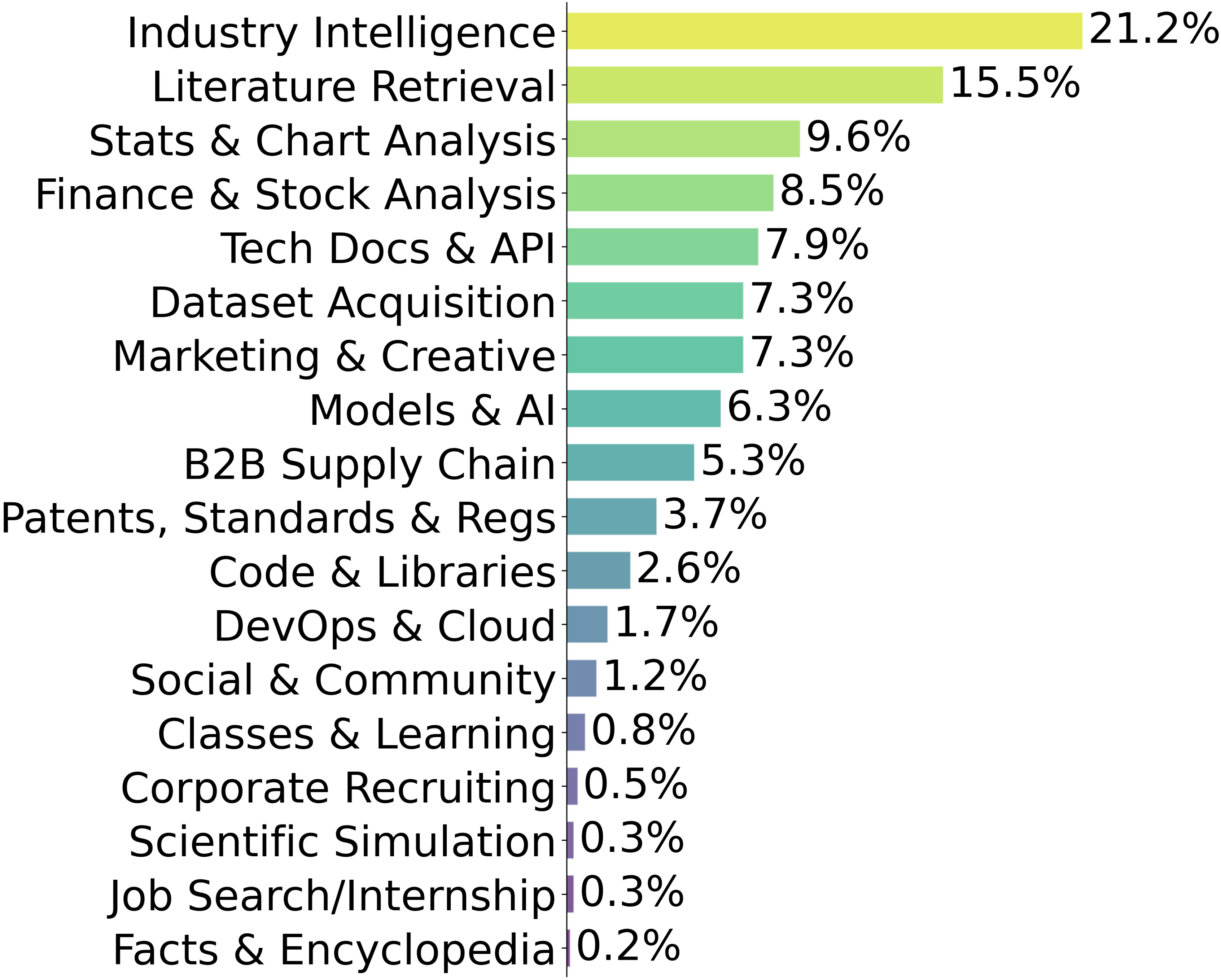
To comprehensively evaluate web agent capabilities, we design three protocols reflecting realistic deployment scenarios. Protocol I
assesses fundamental navigation ability by measuring whether agents can reach target pages given user tasks. Protocol II evaluates navigation
performance when agents are provided with operational documentation. For Protocol II, operational knowledge is consolidated
into structured documentation through a closed-loop framework. Web agents first generate action trajectories for target tasks, which NavEval
evaluates automatically. Correct trajectories proceed to annotation, while incorrect ones are regenerated until reaching retry limits, after
which human annotators refine them. The annotation platform further verifies accepted trajectories and streamlines redundant operations.
Finally, LLMs generate operation manuals from these refined trajectories, completing the documentation pipeline. While Protocols I and II
focus on navigation, realistic web environments require capabilities beyond page navigation. Agents must demonstrate deep page understanding,
multi-source information integration, and precise extraction capabilities critical for holistic evaluation. Protocol III mirrors realistic
deployment by assessing whether agents can accurately retrieve target information across multiple modalities (text, documents, charts).
Based on these designs, we collect 1,000, 1,000, and 100 tasks for Protocols I, II, and III, respectively. Notably, Protocols I and II share 550 overlapping
tasks, with the sole difference being the availability of operational documentation.
 Workflow of the semi-automated pipeline for constructing operational documentation in Protocol II. The process integrates automated exploration, evaluation, manual refinement, and LLM-based generation to produce high-quality operational documentation.
Workflow of the semi-automated pipeline for constructing operational documentation in Protocol II. The process integrates automated exploration, evaluation, manual refinement, and LLM-based generation to produce high-quality operational documentation.